Entity Embeddings of Categorical Variables using TensorFlow
Source:vignettes/Applications/Tensorflow.Rmd
Tensorflow.RmdThe approach encodes categorical data as multiple numeric variables using a word embedding approach. Originally intended as a way to take a large number of word identifiers and represent them in a smaller dimension. Good references on this are Guo and Berkhahn (2016) and Chapter 6 of Francois and Allaire (2018).
The methodology first translates the C factor levels as a
set of integer values then randomly allocates them to the new D
numeric columns. These columns are optionally connected in a neural
network to an intermediate layer of hidden units. Optionally, other
predictors can be added to the network in the usual way (via the
predictors argument) that also link to the hidden layer.
This implementation uses a single layer with ReLu activations. Finally,
an output layer is used with either linear activation (for numeric
outcomes) or softmax (for classification).
To translate this model to a set of embeddings, the coefficients of the original embedding layer are used to represent the original factor levels.
As an example, we use the Ames housing data where the sale price of houses are being predicted. One predictor, neighborhood, has the most factor levels of the predictors.
library(tidymodels)
data(ames)
length(levels(ames$Neighborhood))## [1] 29The distribution of data in the neighborhood is not uniform:
ames |>
count(Neighborhood) |>
ggplot(aes(n, reorder(Neighborhood, n))) +
geom_col() +
labs(y = NULL) +
theme_bw()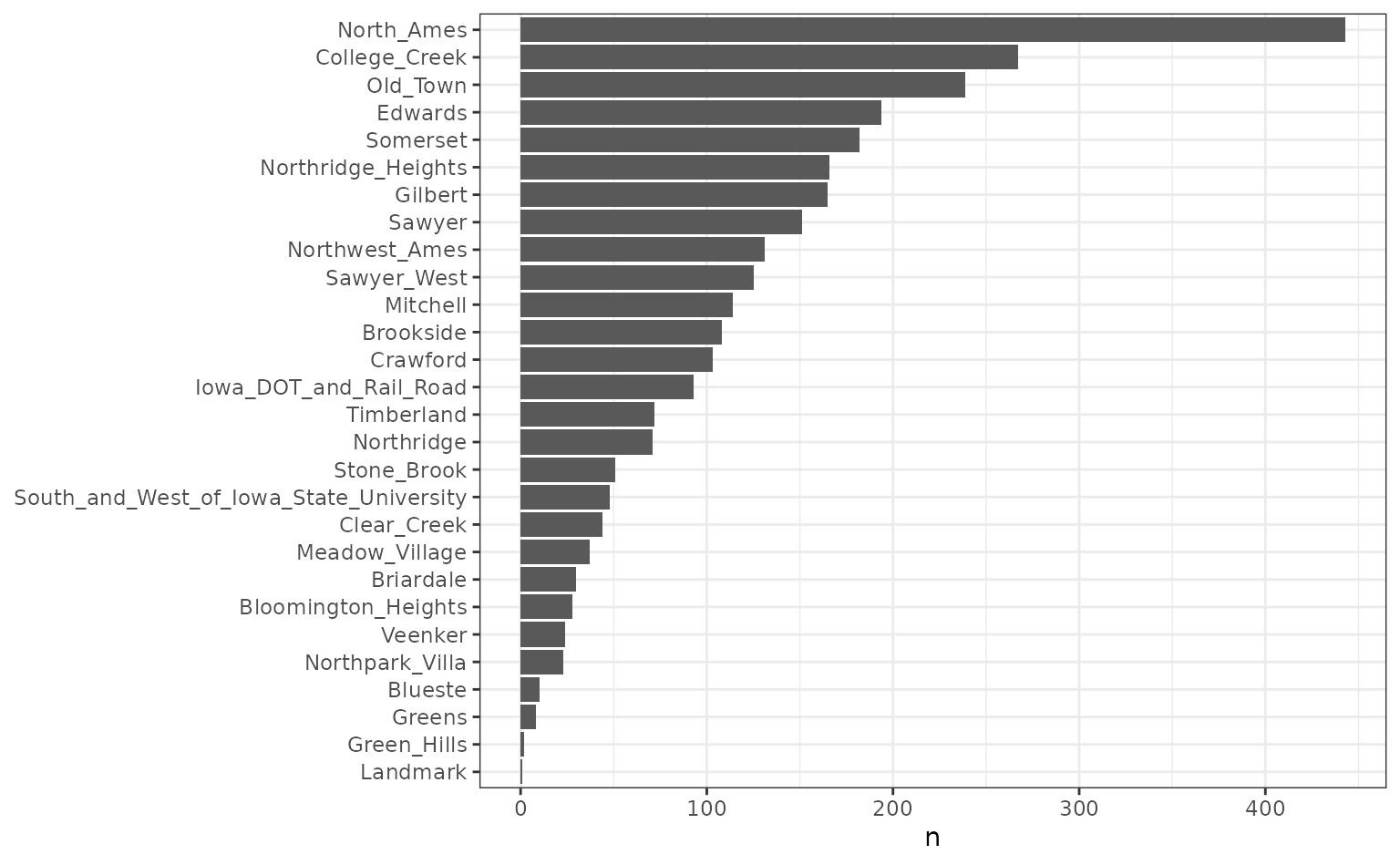
Fo plotting later, we calculate the simple means per neighborhood:
means <-
ames |>
group_by(Neighborhood) |>
summarise(
mean = mean(log10(Sale_Price)),
n = length(Sale_Price),
lon = median(Longitude),
lat = median(Latitude)
)We’ll fit a model with 10 hidden units and 3 encoding columns:
library(embed)
tf_embed <-
recipe(Sale_Price ~ ., data = ames) |>
step_log(Sale_Price, base = 10) |>
# Add some other predictors that can be used by the network
# We preprocess them first
step_YeoJohnson(Lot_Area, Full_Bath, Gr_Liv_Area) |>
step_range(Lot_Area, Full_Bath, Gr_Liv_Area) |>
step_embed(
Neighborhood,
outcome = vars(Sale_Price),
predictors = vars(Lot_Area, Full_Bath, Gr_Liv_Area),
num_terms = 5,
hidden_units = 10,
options = embed_control(epochs = 75, validation_split = 0.2)
) |>
prep(training = ames)
theme_set(theme_bw() + theme(legend.position = "top"))
tf_embed$steps[[4]]$history |>
filter(epochs > 1) |>
ggplot(aes(x = epochs, y = loss, col = type)) +
geom_line() +
scale_y_log10()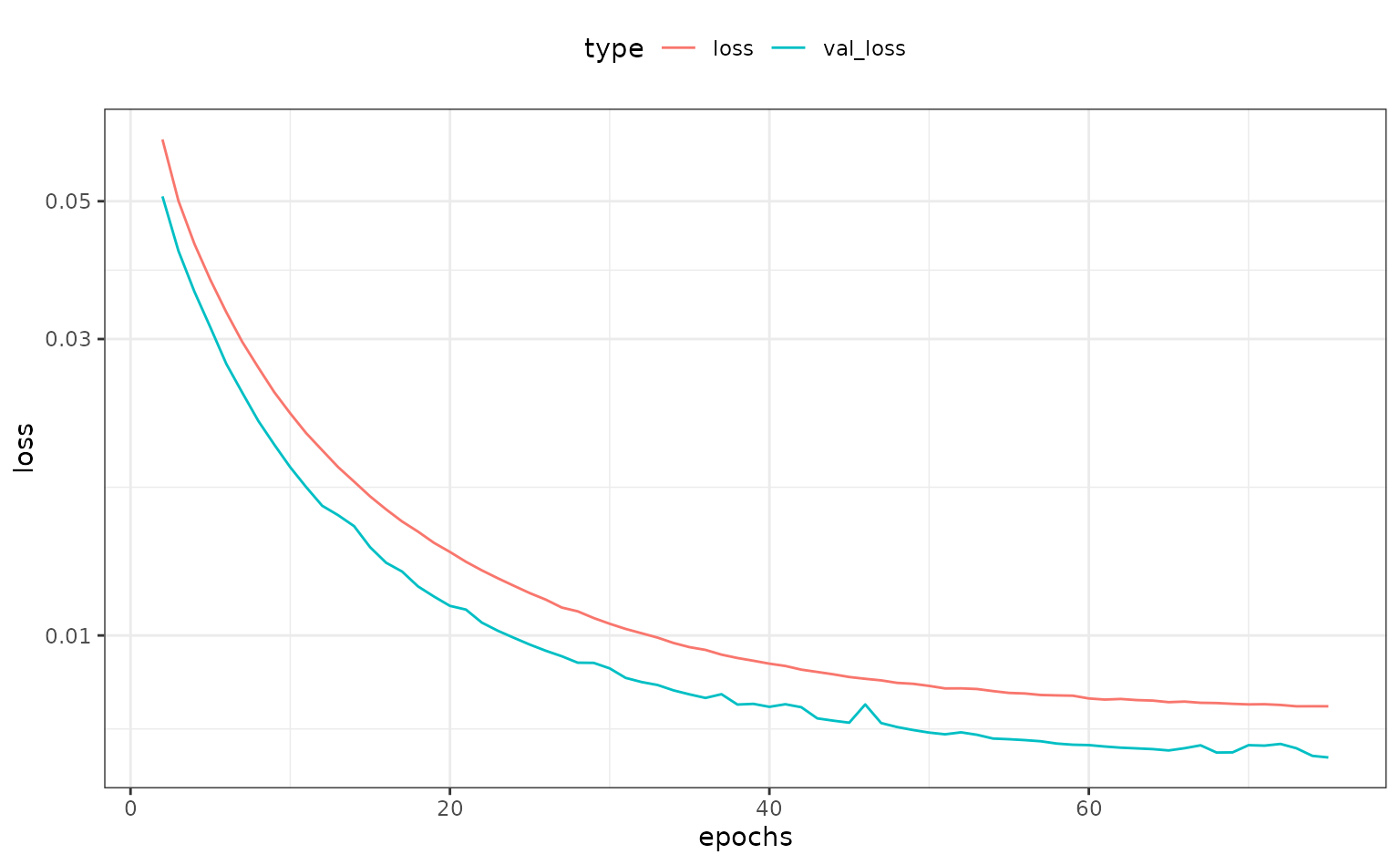
The embeddings are obtained using the tidy method:
hood_coef <-
tidy(tf_embed, number = 4) |>
dplyr::select(-terms, -id) |>
dplyr::rename(Neighborhood = level) |>
# Make names smaller
rename_at(
vars(contains("emb")),
funs(gsub("Neighborhood_", "", ., fixed = TRUE))
)
hood_coef## # A tibble: 30 × 6
## embed_1 embed_2 embed_3 embed_4 embed_5 Neighborhood
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 -0.0102 -0.0239 -0.0220 -0.0306 -0.0211 ..new
## 2 -0.0196 -0.0232 -0.00193 -0.0181 0.0329 North_Ames
## 3 -0.0445 -0.0378 -0.0279 -0.0234 -0.0496 College_Creek
## 4 -0.0358 0.0287 0.0114 0.0380 0.0750 Old_Town
## 5 -0.0503 0.0560 0.0221 0.0268 0.0488 Edwards
## 6 -0.0232 -0.121 -0.0375 -0.0160 -0.0756 Somerset
## 7 -0.0474 -0.0457 -0.0362 -0.0664 -0.161 Northridge_Heights
## 8 0.0192 -0.00966 0.0150 -0.0422 -0.0216 Gilbert
## 9 -0.0628 -0.0252 -0.00954 0.00523 0.0362 Sawyer
## 10 -0.0322 -0.0390 0.0107 -0.0122 0.0166 Northwest_Ames
## # ℹ 20 more rows
hood_coef <-
hood_coef |>
inner_join(means, by = "Neighborhood")
hood_coef## # A tibble: 28 × 10
## embed_1 embed_2 embed_3 embed_4 embed_5 Neighborhood mean n
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <int>
## 1 -0.0196 -0.0232 -0.00193 -0.0181 0.0329 North_Ames 5.15 443
## 2 -0.0445 -0.0378 -0.0279 -0.0234 -0.0496 College_Cre… 5.29 267
## 3 -0.0358 0.0287 0.0114 0.0380 0.0750 Old_Town 5.07 239
## 4 -0.0503 0.0560 0.0221 0.0268 0.0488 Edwards 5.09 194
## 5 -0.0232 -0.121 -0.0375 -0.0160 -0.0756 Somerset 5.35 182
## 6 -0.0474 -0.0457 -0.0362 -0.0664 -0.161 Northridge_… 5.49 166
## 7 0.0192 -0.00966 0.0150 -0.0422 -0.0216 Gilbert 5.27 165
## 8 -0.0628 -0.0252 -0.00954 0.00523 0.0362 Sawyer 5.13 151
## 9 -0.0322 -0.0390 0.0107 -0.0122 0.0166 Northwest_A… 5.27 131
## 10 -0.0614 -0.0418 -0.0289 0.0296 -0.00234 Sawyer_West 5.25 125
## # ℹ 18 more rows
## # ℹ 2 more variables: lon <dbl>, lat <dbl>We can make a simple, interactive plot of the new features versus the outcome:
tf_plot <-
hood_coef |>
dplyr::select(-lon, -lat) |>
gather(variable, value, starts_with("embed")) |>
# Clean up the embedding names
# Add a new variable as a hover-over/tool tip
mutate(
label = paste0(gsub("_", " ", Neighborhood), " (n=", n, ")"),
variable = gsub("_", " ", variable)
) |>
ggplot(aes(x = value, y = mean)) +
geom_point_interactive(aes(size = sqrt(n), tooltip = label), alpha = .5) +
facet_wrap(~variable, scales = "free_x") +
theme_bw() +
theme(legend.position = "top") +
labs(y = "Mean (log scale)", x = "Embedding")
girafe(ggobj = tf_plot)However, this has induced some between-predictor correlations:
## embed_1 embed_2 embed_3 embed_4 embed_5
## embed_1 1.00 0.15 0.23 -0.26 0.21
## embed_2 0.15 1.00 0.17 0.38 0.47
## embed_3 0.23 0.17 1.00 -0.11 0.10
## embed_4 -0.26 0.38 -0.11 1.00 0.53
## embed_5 0.21 0.47 0.10 0.53 1.00